
We had a database failure causing a production outage. Both master and slave databases have failed, slave became unresponsive and the master switched to read-only mode. By the look of it the slave database failed first and possibly caused the master to switch to read-only mode. The sequence of events was:
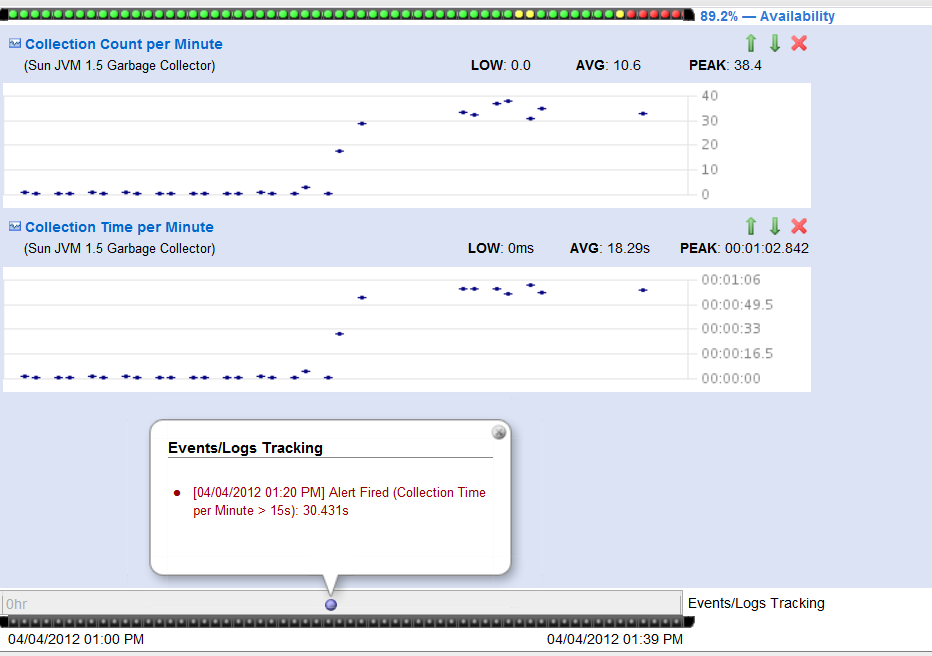
13:20 - our monitoring reported GC time per minute on the SLAVE instance over 30 seconds. The GC time on the slave instance continued to grow rapidly until it reached almost 1 minute per minute, at which point the process is essentially hanging - see attached screenshot.
13:22:43 - 13:25:43 - MASTER instance stopped responding to write requests. All requests sent to the database during 3 minutes between 13:22:43 and 13:25:43 returned at 13:25:44 with Exception:
[ObjectDB 2.3.7_08] javax.persistence.PersistenceException
Connection is closed (error 526)
at com.objectdb.jpa.EMImpl.merge(EMImpl.java:456)
at sun.reflect.GeneratedMethodAccessor528.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:616)
at org.springframework.orm.jpa.SharedEntityManagerCreator$SharedEntityManagerInvocationHandler.invoke(SharedEntityManagerCreator.java:240)
..............................................................
Caused by: com.objectdb.o.UserException: Connection is closed
at com.objectdb.o.MSG.d(MSG.java:61)
at com.objectdb.o.NTS.v(NTS.java:204)
at com.objectdb.o.RPT.f(RPT.java:220)
at com.objectdb.o.RPT.Vp(RPT.java:203)
at com.objectdb.o.WSN.h(WSN.java:930)
at com.objectdb.o.WSN.UC(WSN.java:238)
at com.objectdb.o.STC.m(STC.java:346)
at com.objectdb.o.SHN.ae(SHN.java:410)
at com.objectdb.o.SHN.K(SHN.java:139)
at com.objectdb.o.HND.run(HND.java:133)
at java.lang.Thread.run(Unknown Source) The reading continued to work and there was nothing in the server DB logs.
All write requests sent to master after this time have failed with the same exception.
13:25:59 - the slave closed it's database - the following was in the logs:
[2012-04-04 19:25:59 #4 store]
Database '/opt/objectdb/db/$replication/contextspace.odb' is closed by 30752@hardhead
We did not see anything wrong in the monitoring data for the master instance. We do collect quite a lot of monitoring data, so if you would like to see anything specific, please let me know.
The load was not particularly high and there was nothing unusual otherwise.
This was a production outage, so the focus was on restoring the service and we did not take heap dumps etc. We cannot reproduce the issue.
The main questions we have are:
- Is it possible for the slave instance to impact the master instance in any way?
- Under which circumstances would the master DB switch to read-only mode?
Natalia.

{kind=link}