Hi,
We've run another test today with large initial DB size, to avoid resizing. The initial size was set to 4.5GB. It was running great for 6 hours and after that the performance destabilised and did not recover again. As before, most of requests were OK, but there were also a lot of very slow requests.
The db config is as follows:
<general>
<temp path="$temp/ObjectDB" threshold="8mb" />
<network inactivity-timeout="0" />
<url-history size="50" user="true" password="true" />
<log path="$objectdb/log/" max="8mb" stdout="false" stderr="false" />
<log-archive path="$objectdb/log/archive/" retain="90" />
<logger name="*" level="info" />
</general>
<database>
<size initial="4608mb" resize="256mb" page="2kb" />
<recovery enabled="true" sync="false" path="." max="128mb" />
<recording enabled="false" sync="false" path="." mode="write" />
<locking version-check="true" />
<processing cache="8mb" max-threads="400" />
<query-cache results="8mb" programs="500" />
<extensions drop="temp,tmp" />
<activation code="AMTF-SC4T-GR1Y-XCJT-EKKB" />
</database>
<entities>
<enhancement agent="false" reflection="warning" />
<cache ref="weak" level2="0" />
<persist serialization="false" />
<cascade-persist always="auto" on-persist="false" on-commit="true" />
<dirty-tracking arrays="false" />
</entities>
<server>
<connection port="6136" max="1000" />
<data path="$objectdb/db" />
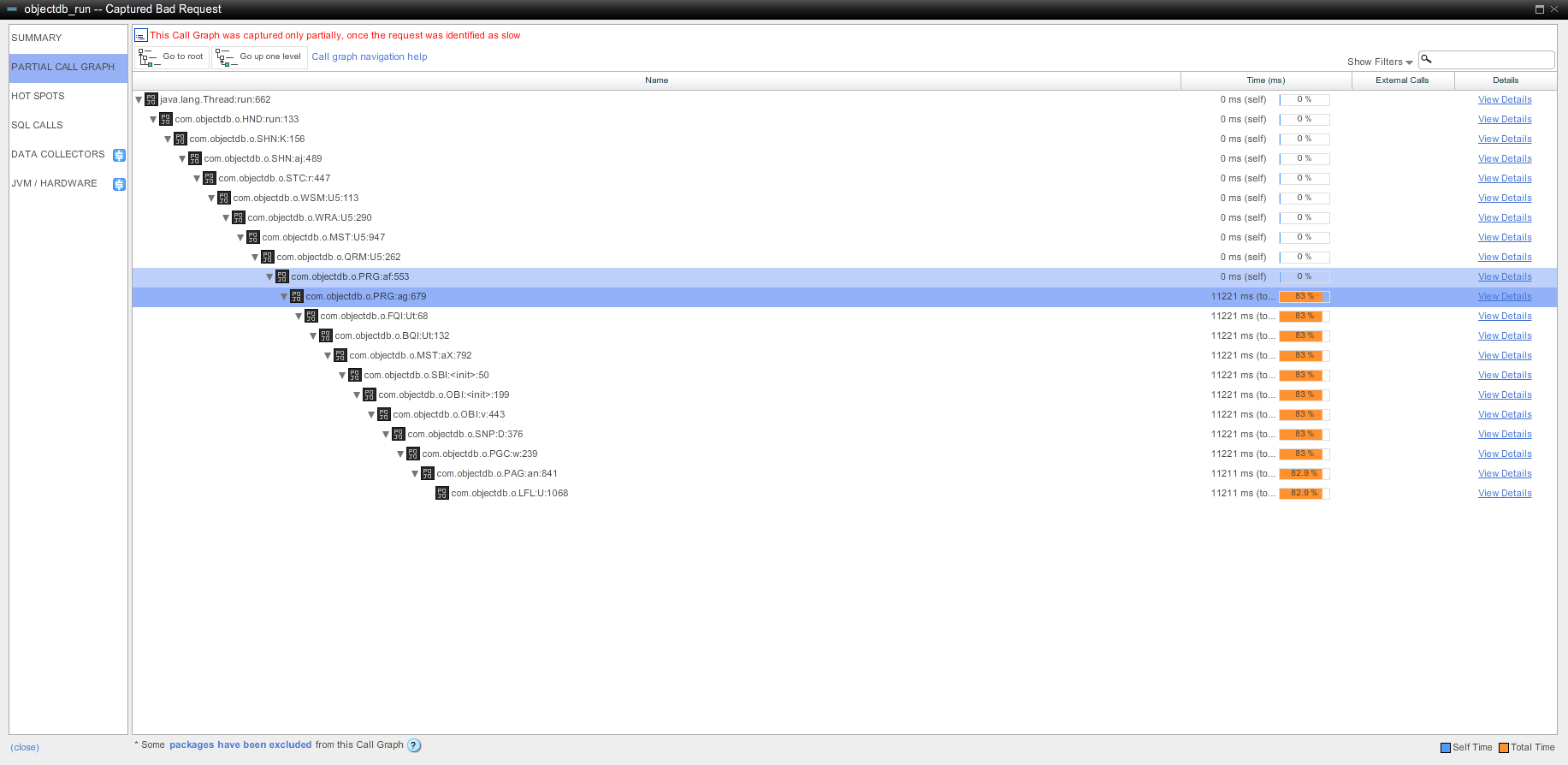
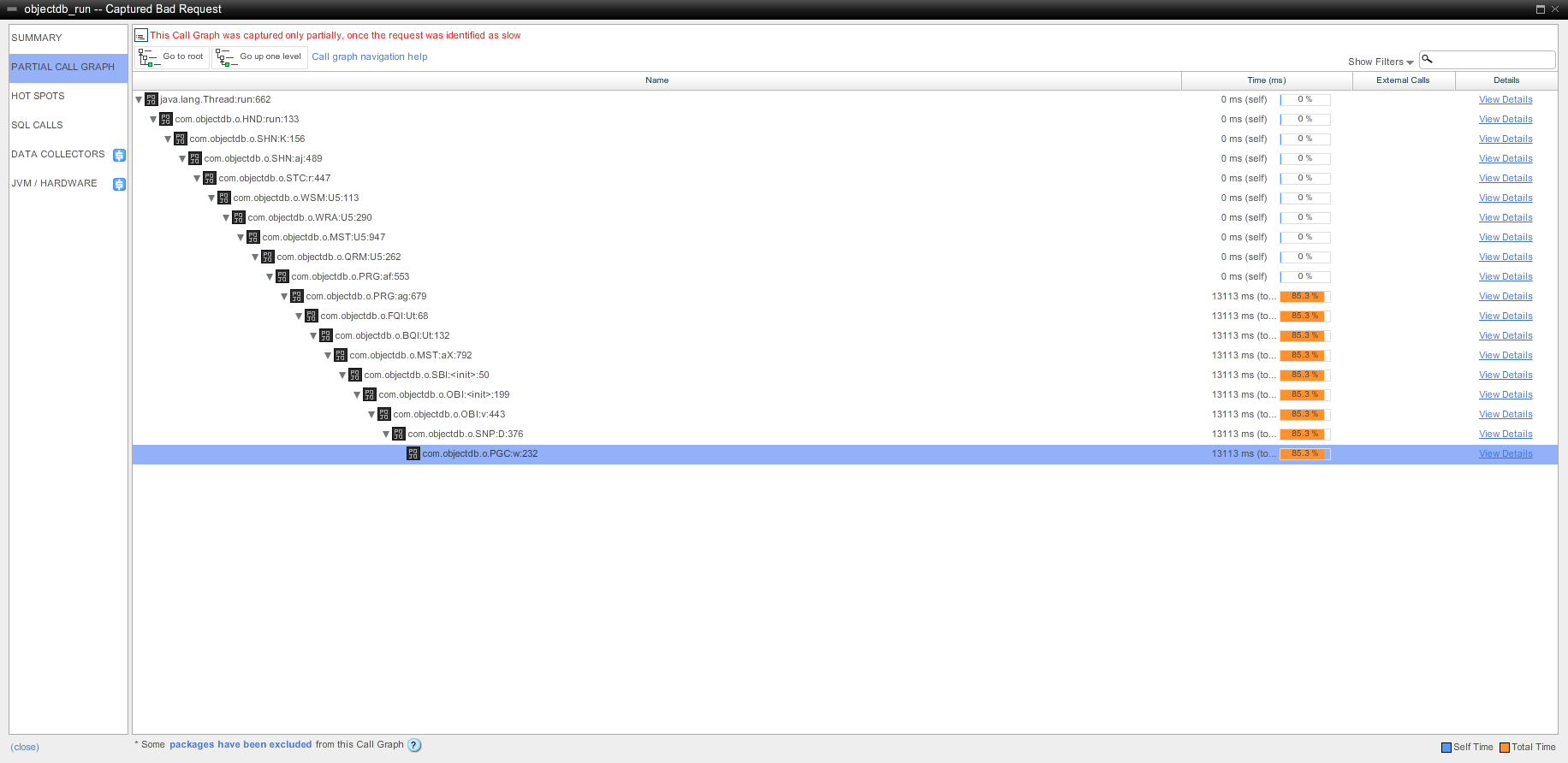
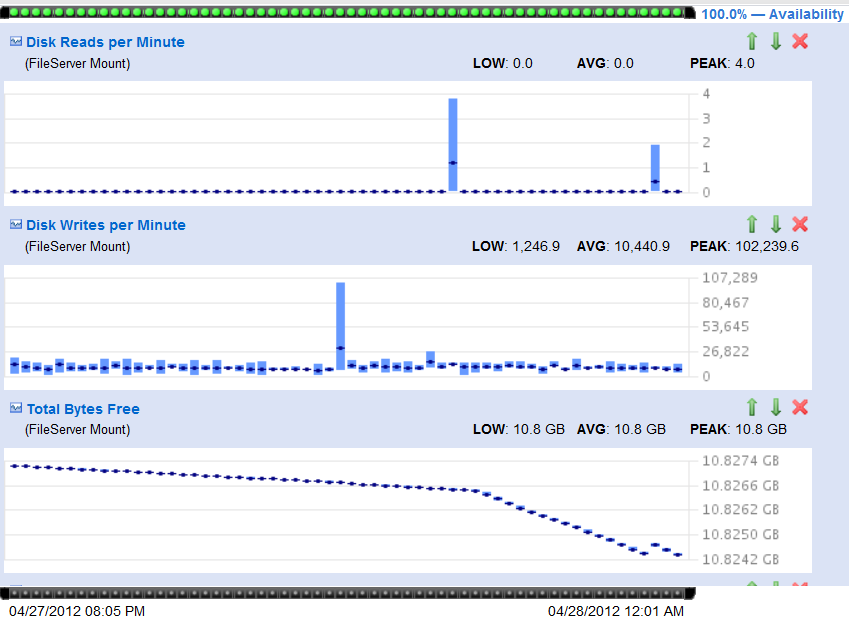
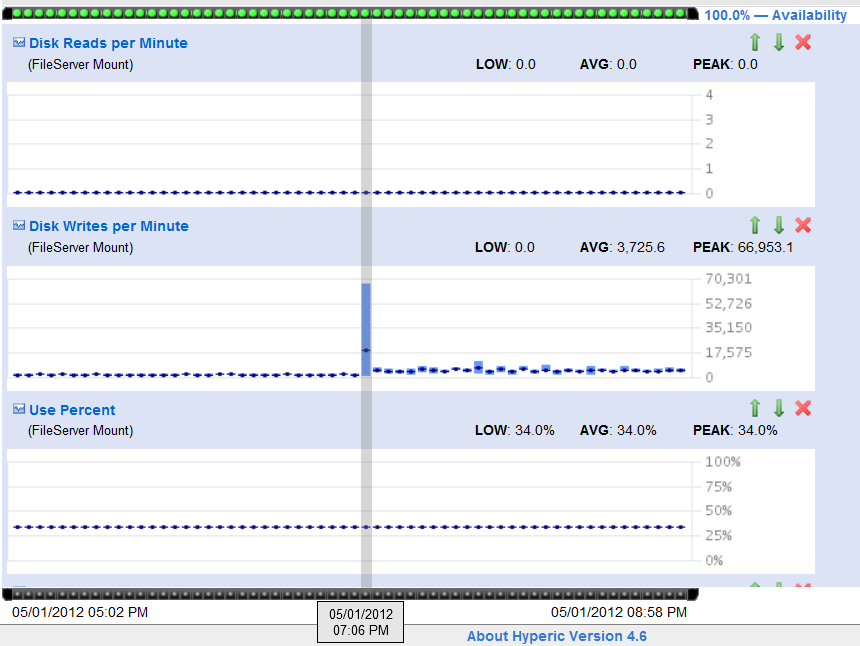
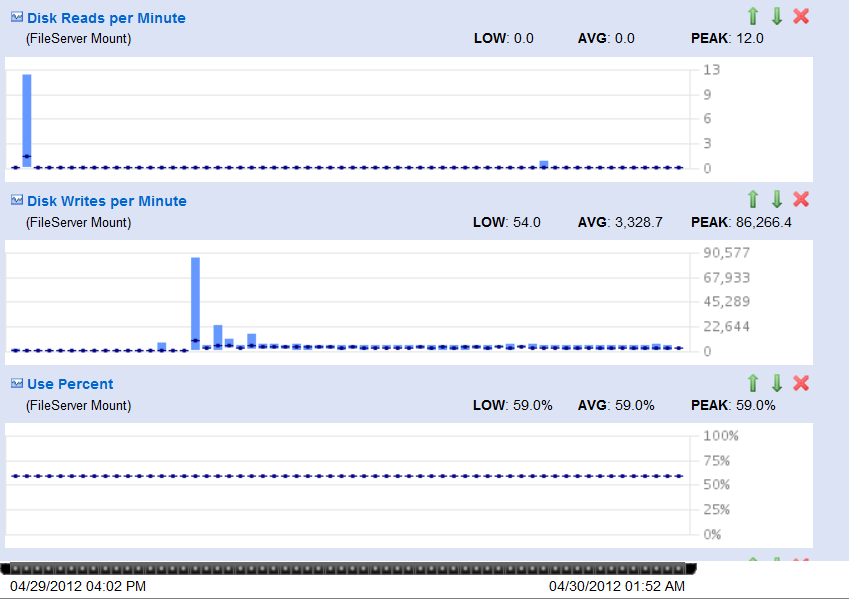
</server> I've looked at it with AppDynamics again and could see that it gets stuck in 3 different places, which are all different from last time. Please see the attached callgraphs for details. One of these places is java.io.RandomAccessFile:writeBytes, which takes up to 10 seconds. I've also noticed a large IO write spike at the same time the issue has started (picture also attached), but after that IO looked normal. As before, this is a constant load, so the issues is not related to any particular query. Also, I've made a mistake in the last post regarding load we are running - the load is 120000 call per minute, counting every call to com.objectdb.o.SHN:K method.
Is there anything in the DB apart from the resizing that can cause large file writes? I would estimate the size of actual data in the db file to be around 2 - 2.5 Gb. Are there any limits we could hit?
Also, another question - would it make sense to try different page size? What effect does it have?
Any advice much appreciated,
Regards,
Natalia.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}