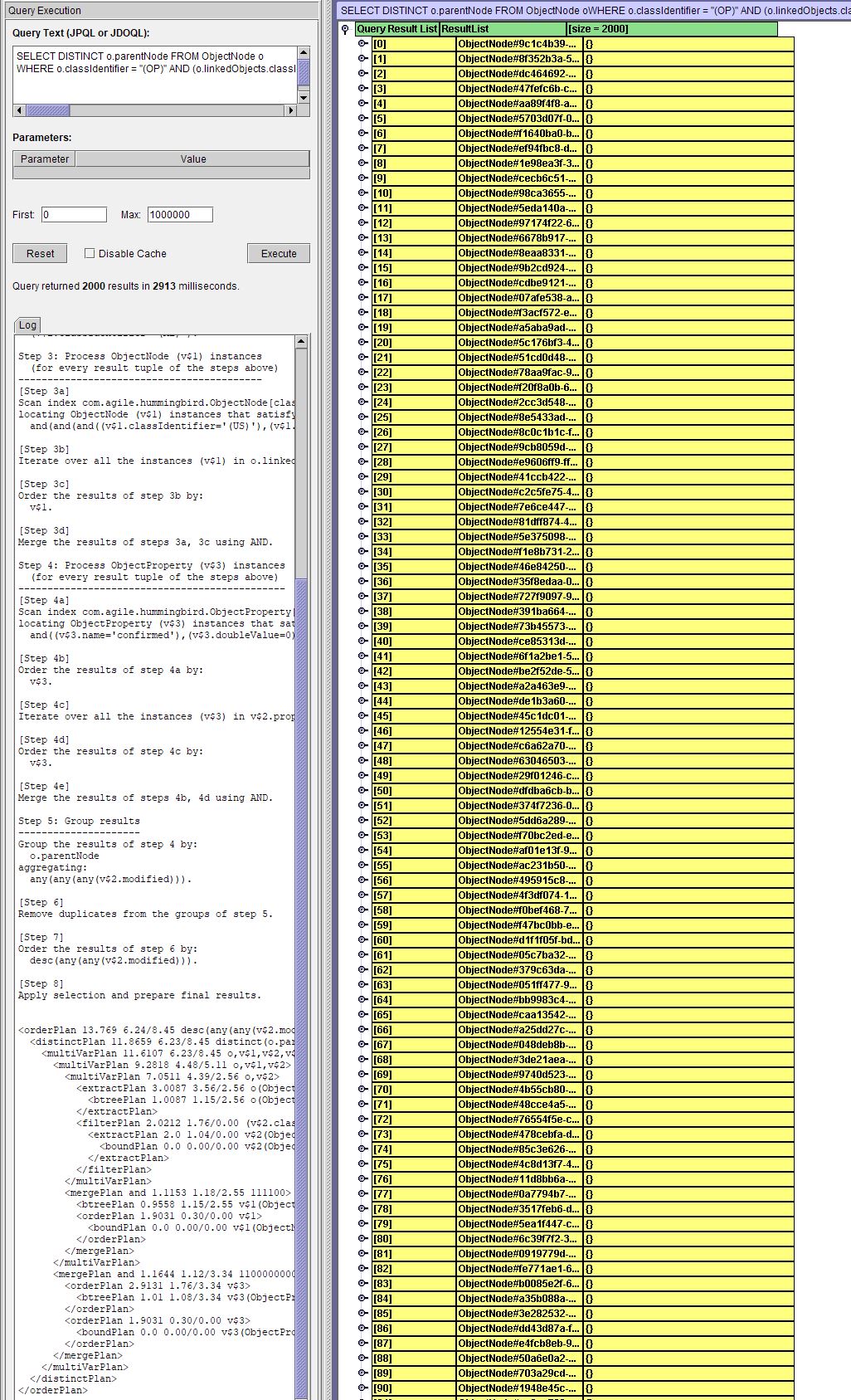
You can see all the query plans in the log if you enable logging for queries in trace level:
<logger name="query" level="trace" />
It is shown as a <finalPlans> xml element with child for each query plan:
(however, it may be easier just to try running the query several times in the Explorer with the position hint: 1, 2, 3, 4, 5 as explained above).
<finalPlans>
<groupPlan plan="group([a.endDate,v$1.nodePath,v$3.doubleValue],extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:bound(a.objectsInCharge)) <x> v$2:filter(index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)]),(v$1.linkedObjects join v$2)) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')))" eval="9.2895" group="group(a.endDate,v$1.nodePath,v$3.doubleValue)" eval="[]">
<multiVarPlan plan="extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:bound(a.objectsInCharge)) <x> v$2:filter(index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)]),(v$1.linkedObjects join v$2)) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="9.0342">
<multiVarPlan plan="extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:bound(a.objectsInCharge)) <x> v$2:filter(index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)]),(v$1.linkedObjects join v$2))" eval="6.9918">
<extractPlan plan="extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:bound(a.objectsInCharge))" eval="4.9675" variable="v$1">
<multiVarPlan plan="a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:bound(a.objectsInCharge)" eval="2.9675">
<extractPlan plan="extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull]))" eval="2.9675" variable="a">
<btreePlan plan="index(esst[3_3_0_2018-07-20->3_3_0:notNull])" eval="0.9675" variable="a" />
</extractPlan>
<boundPlan plan="bound(a.objectsInCharge)" eval="0.0" variable="v$1" />
</multiVarPlan>
</extractPlan>
<filterPlan plan="filter(index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)]),(v$1.linkedObjects join v$2))" eval="1.0122">
<btreePlan plan="index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)])" eval="0.991" variable="v$2" />
</filterPlan>
</multiVarPlan>
<filterPlan plan="filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="1.0212">
<extractPlan plan="extract(v$3,type(ObjectProperty[set]))" eval="1.0" variable="v$3">
<btreePlan plan="type(ObjectProperty[set])" eval="1.0" variable="v$3" />
</extractPlan>
</filterPlan>
</multiVarPlan>
</groupPlan>
<groupPlan plan="group([a.endDate,v$1.nodePath,v$3.doubleValue],extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:bound(a.objectsInCharge)) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')) <x> v$2:filter(filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP')),(v$2.classIdentifier='(TC)')))" eval="9.3923" group="group(a.endDate,v$1.nodePath,v$3.doubleValue)" eval="[]">
<multiVarPlan plan="extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:bound(a.objectsInCharge)) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')) <x> v$2:filter(filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP')),(v$2.classIdentifier='(TC)'))" eval="9.137">
<multiVarPlan plan="extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:bound(a.objectsInCharge)) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="7.0099">
<extractPlan plan="extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:bound(a.objectsInCharge))" eval="4.9675" variable="v$1">
<multiVarPlan plan="a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:bound(a.objectsInCharge)" eval="2.9675">
<extractPlan plan="extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull]))" eval="2.9675" variable="a">
<btreePlan plan="index(esst[3_3_0_2018-07-20->3_3_0:notNull])" eval="0.9675" variable="a" />
</extractPlan>
<boundPlan plan="bound(a.objectsInCharge)" eval="0.0" variable="v$1" />
</multiVarPlan>
</extractPlan>
<filterPlan plan="filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="1.0212">
<extractPlan plan="extract(v$3,type(ObjectProperty[set]))" eval="1.0" variable="v$3">
<btreePlan plan="type(ObjectProperty[set])" eval="1.0" variable="v$3" />
</extractPlan>
</filterPlan>
</multiVarPlan>
<filterPlan plan="filter(filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP')),(v$2.classIdentifier='(TC)'))" eval="1.0636">
<filterPlan plan="filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP'))" eval="1.0424">
<filterPlan plan="filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1))" eval="1.0212">
<extractPlan plan="extract(v$2,type(ObjectNode[set]))" eval="1.0" variable="v$2">
<btreePlan plan="type(ObjectNode[set])" eval="1.0" variable="v$2" />
</extractPlan>
</filterPlan>
</filterPlan>
</filterPlan>
</multiVarPlan>
</groupPlan>
<groupPlan plan="group([a.endDate,v$1.nodePath,v$3.doubleValue],extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:type(ObjectNode[set])) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')) <x> v$2:filter(index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)]),(v$1.linkedObjects join v$2)))" eval="9.5905" group="group(a.endDate,v$1.nodePath,v$3.doubleValue)" eval="[]">
<multiVarPlan plan="extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:type(ObjectNode[set])) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')) <x> v$2:filter(index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)]),(v$1.linkedObjects join v$2))" eval="9.3352">
<multiVarPlan plan="extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:type(ObjectNode[set])) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="7.3109">
<extractPlan plan="extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:type(ObjectNode[set]))" eval="5.2685" variable="v$1">
<multiVarPlan plan="a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:type(ObjectNode[set])" eval="5.2685">
<extractPlan plan="extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull]))" eval="2.9675" variable="a">
<btreePlan plan="index(esst[3_3_0_2018-07-20->3_3_0:notNull])" eval="0.9675" variable="a" />
</extractPlan>
<btreePlan plan="type(ObjectNode[set])" eval="1.0" variable="v$1" />
</multiVarPlan>
</extractPlan>
<filterPlan plan="filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="1.0212">
<extractPlan plan="extract(v$3,type(ObjectProperty[set]))" eval="1.0" variable="v$3">
<btreePlan plan="type(ObjectProperty[set])" eval="1.0" variable="v$3" />
</extractPlan>
</filterPlan>
</multiVarPlan>
<filterPlan plan="filter(index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)]),(v$1.linkedObjects join v$2))" eval="1.0122">
<btreePlan plan="index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)])" eval="0.991" variable="v$2" />
</filterPlan>
</multiVarPlan>
</groupPlan>
<groupPlan plan="group([a.endDate,v$1.nodePath,v$3.doubleValue],extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:type(ObjectNode[set])) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')) <x> v$2:filter(filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP')),(v$2.classIdentifier='(TC)')))" eval="9.6933" group="group(a.endDate,v$1.nodePath,v$3.doubleValue)" eval="[]">
<multiVarPlan plan="extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:type(ObjectNode[set])) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')) <x> v$2:filter(filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP')),(v$2.classIdentifier='(TC)'))" eval="9.438">
<multiVarPlan plan="extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:type(ObjectNode[set])) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="7.3109">
<extractPlan plan="extract(v$1,a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:type(ObjectNode[set]))" eval="5.2685" variable="v$1">
<multiVarPlan plan="a:extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull])) <x> v$1:type(ObjectNode[set])" eval="5.2685">
<extractPlan plan="extract(a,index(esst[3_3_0_2018-07-20->3_3_0:notNull]))" eval="2.9675" variable="a">
<btreePlan plan="index(esst[3_3_0_2018-07-20->3_3_0:notNull])" eval="0.9675" variable="a" />
</extractPlan>
<btreePlan plan="type(ObjectNode[set])" eval="1.0" variable="v$1" />
</multiVarPlan>
</extractPlan>
<filterPlan plan="filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="1.0212">
<extractPlan plan="extract(v$3,type(ObjectProperty[set]))" eval="1.0" variable="v$3">
<btreePlan plan="type(ObjectProperty[set])" eval="1.0" variable="v$3" />
</extractPlan>
</filterPlan>
</multiVarPlan>
<filterPlan plan="filter(filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP')),(v$2.classIdentifier='(TC)'))" eval="1.0636">
<filterPlan plan="filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP'))" eval="1.0424">
<filterPlan plan="filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1))" eval="1.0212">
<extractPlan plan="extract(v$2,type(ObjectNode[set]))" eval="1.0" variable="v$2">
<btreePlan plan="type(ObjectNode[set])" eval="1.0" variable="v$2" />
</extractPlan>
</filterPlan>
</filterPlan>
</filterPlan>
</multiVarPlan>
</groupPlan>
<groupPlan plan="group([a.endDate,v$1.nodePath,v$3.doubleValue],extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:bound(a.objectsInCharge)) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')) <x> v$2:filter(index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)]),(v$1.linkedObjects join v$2)))" eval="18.6359" group="group(a.endDate,v$1.nodePath,v$3.doubleValue)" eval="[]">
<multiVarPlan plan="extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:bound(a.objectsInCharge)) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')) <x> v$2:filter(index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)]),(v$1.linkedObjects join v$2))" eval="18.3806">
<multiVarPlan plan="extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:bound(a.objectsInCharge)) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="16.3563">
<extractPlan plan="extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:bound(a.objectsInCharge))" eval="14.3139" variable="v$1">
<multiVarPlan plan="a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:bound(a.objectsInCharge)" eval="12.3139">
<filterPlan plan="filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0))" eval="12.3139">
<filterPlan plan="filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3))" eval="12.2927">
<filterPlan plan="filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3))" eval="12.2715">
<filterPlan plan="filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date))" eval="12.2503">
<extractPlan plan="extract(a,type(Action[all]))" eval="12.2291" variable="a">
<btreePlan plan="type(Action[all])" eval="11.9281" variable="a" />
</extractPlan>
</filterPlan>
</filterPlan>
</filterPlan>
</filterPlan>
<boundPlan plan="bound(a.objectsInCharge)" eval="0.0" variable="v$1" />
</multiVarPlan>
</extractPlan>
<filterPlan plan="filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="1.0212">
<extractPlan plan="extract(v$3,type(ObjectProperty[set]))" eval="1.0" variable="v$3">
<btreePlan plan="type(ObjectProperty[set])" eval="1.0" variable="v$3" />
</extractPlan>
</filterPlan>
</multiVarPlan>
<filterPlan plan="filter(index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)]),(v$1.linkedObjects join v$2))" eval="1.0122">
<btreePlan plan="index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)])" eval="0.991" variable="v$2" />
</filterPlan>
</multiVarPlan>
</groupPlan>
<groupPlan plan="group([a.endDate,v$1.nodePath,v$3.doubleValue],extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:bound(a.objectsInCharge)) <x> v$2:filter(filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP')),(v$2.classIdentifier='(TC)')) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')))" eval="18.7387" group="group(a.endDate,v$1.nodePath,v$3.doubleValue)" eval="[]">
<multiVarPlan plan="extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:bound(a.objectsInCharge)) <x> v$2:filter(filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP')),(v$2.classIdentifier='(TC)')) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="18.4834">
<multiVarPlan plan="extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:bound(a.objectsInCharge)) <x> v$2:filter(filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP')),(v$2.classIdentifier='(TC)'))" eval="16.441">
<extractPlan plan="extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:bound(a.objectsInCharge))" eval="14.3139" variable="v$1">
<multiVarPlan plan="a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:bound(a.objectsInCharge)" eval="12.3139">
<filterPlan plan="filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0))" eval="12.3139">
<filterPlan plan="filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3))" eval="12.2927">
<filterPlan plan="filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3))" eval="12.2715">
<filterPlan plan="filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date))" eval="12.2503">
<extractPlan plan="extract(a,type(Action[all]))" eval="12.2291" variable="a">
<btreePlan plan="type(Action[all])" eval="11.9281" variable="a" />
</extractPlan>
</filterPlan>
</filterPlan>
</filterPlan>
</filterPlan>
<boundPlan plan="bound(a.objectsInCharge)" eval="0.0" variable="v$1" />
</multiVarPlan>
</extractPlan>
<filterPlan plan="filter(filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP')),(v$2.classIdentifier='(TC)'))" eval="1.0636">
<filterPlan plan="filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP'))" eval="1.0424">
<filterPlan plan="filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1))" eval="1.0212">
<extractPlan plan="extract(v$2,type(ObjectNode[set]))" eval="1.0" variable="v$2">
<btreePlan plan="type(ObjectNode[set])" eval="1.0" variable="v$2" />
</extractPlan>
</filterPlan>
</filterPlan>
</filterPlan>
</multiVarPlan>
<filterPlan plan="filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="1.0212">
<extractPlan plan="extract(v$3,type(ObjectProperty[set]))" eval="1.0" variable="v$3">
<btreePlan plan="type(ObjectProperty[set])" eval="1.0" variable="v$3" />
</extractPlan>
</filterPlan>
</multiVarPlan>
</groupPlan>
<groupPlan plan="group([a.endDate,v$1.nodePath,v$3.doubleValue],extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:type(ObjectNode[set])) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')) <x> v$2:filter(index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)]),(v$1.linkedObjects join v$2)))" eval="18.9369" group="group(a.endDate,v$1.nodePath,v$3.doubleValue)" eval="[]">
<multiVarPlan plan="extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:type(ObjectNode[set])) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')) <x> v$2:filter(index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)]),(v$1.linkedObjects join v$2))" eval="18.6816">
<multiVarPlan plan="extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:type(ObjectNode[set])) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="16.6573">
<extractPlan plan="extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:type(ObjectNode[set]))" eval="14.6149" variable="v$1">
<multiVarPlan plan="a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:type(ObjectNode[set])" eval="14.6149">
<filterPlan plan="filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0))" eval="12.3139">
<filterPlan plan="filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3))" eval="12.2927">
<filterPlan plan="filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3))" eval="12.2715">
<filterPlan plan="filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date))" eval="12.2503">
<extractPlan plan="extract(a,type(Action[all]))" eval="12.2291" variable="a">
<btreePlan plan="type(Action[all])" eval="11.9281" variable="a" />
</extractPlan>
</filterPlan>
</filterPlan>
</filterPlan>
</filterPlan>
<btreePlan plan="type(ObjectNode[set])" eval="1.0" variable="v$1" />
</multiVarPlan>
</extractPlan>
<filterPlan plan="filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="1.0212">
<extractPlan plan="extract(v$3,type(ObjectProperty[set]))" eval="1.0" variable="v$3">
<btreePlan plan="type(ObjectProperty[set])" eval="1.0" variable="v$3" />
</extractPlan>
</filterPlan>
</multiVarPlan>
<filterPlan plan="filter(index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)]),(v$1.linkedObjects join v$2))" eval="1.0122">
<btreePlan plan="index(ctso['(TC)'_1->'(TC)'_1:and((v$2.objectNameUpper='SETUP'),notNull)])" eval="0.991" variable="v$2" />
</filterPlan>
</multiVarPlan>
</groupPlan>
<groupPlan plan="group([a.endDate,v$1.nodePath,v$3.doubleValue],extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:type(ObjectNode[set])) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')) <x> v$2:filter(filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP')),(v$2.classIdentifier='(TC)')))" eval="19.0397" group="group(a.endDate,v$1.nodePath,v$3.doubleValue)" eval="[]">
<multiVarPlan plan="extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:type(ObjectNode[set])) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot')) <x> v$2:filter(filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP')),(v$2.classIdentifier='(TC)'))" eval="18.7844">
<multiVarPlan plan="extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:type(ObjectNode[set])) <x> v$3:filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="16.6573">
<extractPlan plan="extract(v$1,a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:type(ObjectNode[set]))" eval="14.6149" variable="v$1">
<multiVarPlan plan="a:filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0)) <x> v$1:type(ObjectNode[set])" eval="14.6149">
<filterPlan plan="filter(filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3)),(a.type=0))" eval="12.3139">
<filterPlan plan="filter(filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3)),(a.subType=3))" eval="12.2927">
<filterPlan plan="filter(filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date)),(a.state=3))" eval="12.2715">
<filterPlan plan="filter(extract(a,type(Action[all])),(a.endDate>=current-java.sql.Date))" eval="12.2503">
<extractPlan plan="extract(a,type(Action[all]))" eval="12.2291" variable="a">
<btreePlan plan="type(Action[all])" eval="11.9281" variable="a" />
</extractPlan>
</filterPlan>
</filterPlan>
</filterPlan>
</filterPlan>
<btreePlan plan="type(ObjectNode[set])" eval="1.0" variable="v$1" />
</multiVarPlan>
</extractPlan>
<filterPlan plan="filter(extract(v$3,type(ObjectProperty[set])),(v$3.name='scheduledSlot'))" eval="1.0212">
<extractPlan plan="extract(v$3,type(ObjectProperty[set]))" eval="1.0" variable="v$3">
<btreePlan plan="type(ObjectProperty[set])" eval="1.0" variable="v$3" />
</extractPlan>
</filterPlan>
</multiVarPlan>
<filterPlan plan="filter(filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP')),(v$2.classIdentifier='(TC)'))" eval="1.0636">
<filterPlan plan="filter(filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1)),(v$2.objectNameUpper='SETUP'))" eval="1.0424">
<filterPlan plan="filter(extract(v$2,type(ObjectNode[set])),(v$2.type=1))" eval="1.0212">
<extractPlan plan="extract(v$2,type(ObjectNode[set]))" eval="1.0" variable="v$2">
<btreePlan plan="type(ObjectNode[set])" eval="1.0" variable="v$2" />
</extractPlan>
</filterPlan>
</filterPlan>
</filterPlan>
</multiVarPlan>
</groupPlan>
</finalPlans> 

{kind=link}